文字コードの解説です。
文字コード
1. 文字コードの意味
文字コードとは文字に割り当てた番号のことです。例えばアルファベットの「A」は65、「B」は66と決めておきます。
文字をファイルに保存する時やインターネットでやり取りする時に、この番号で行います。
このように番号を決めておけば65なら「A」、66なら「B」だとわかります。
一般的に文字コードは16進数で表現されます。
2. 16進数
普段の生活で私たちは、0〜9までの10種類の数字を使った10進数を使っています。0,1,2,3・・・,9の次は1桁増えて10となります。
16進数は0〜9までの数字10個と、A,B,C,D,E,Fのアルファベット6個の合計16個を使って表現します。
0,1,2,3・・・,9の次はAとなり、その次はB、その次はCとなり、同様にD,E,Fとなって、その次は1桁増えて10となります。
表にすると
![]()
となります。
16進数の10が10進数の16に該当します。
なぜこのような16進数を使うかというと、2進数の4桁が16進数の1桁にちょうど対応し扱いが簡単だからです。
2進数では0と1の数字2個を使って表現します。
0,1の次は1桁増えて10となります。
表にすると
![]()
となります。
コンピュータ内部では1ビット(bit)を最小単位として0と1を表現します。このビットが8個で1バイト(Byte)となります。
コンピュータはバイト単位でデータを扱いますが、16進数だと端数がでないで表現できます。1バイトの最大値はFFで、+1すると100になり1桁増えます。これを10進数で表現しようとすると、1バイトの最大値は255で、+1しても256となり、切がよくありません。
まとめると、
1バイト=8ビット=2進数で0〜11111111(1が8個)=16進数で0〜FF
難しいことを書きましたが、フォントを作成するにあたり、「16進数では9の次はAとなり、次は順にB,C,D,E,Fとなり、その次は10となる。1Fの次は20、FFの次は100」となることを覚えておけば大丈夫です。
3. 文字コードの種類
文字コードとは文字に割り当てた番号と説明しましたが、この割り当て方法としてシフトJISコード、ユニコード(Unicode)などいろいろな種類があります。
3.1 ASCIIコード
ASCIIとは、American Standard Code for Information Interchange(情報交換用米国標準コード)の略称でアスキーと読みます。
アメリカで定められた、情報交換を目的とした文字コードです。
16進数で00〜7Fまでの範囲に割り当てられています。
00〜1Fは制御コード、20は空白文字(スペース)、21〜7Eは文字、7Fは制御コード(DEL)です。
表で示すと下のようになります。
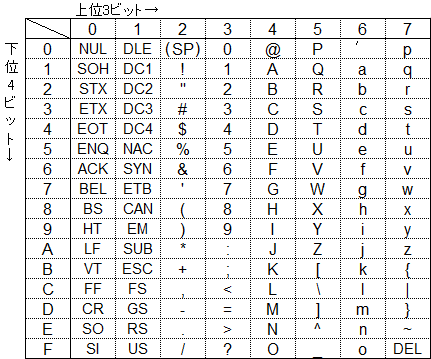
例えば「A」という文字は、上位3ビットが「4」、下位4ビットが「1」のところにあるので、文字コードは41となります。
制御コードは制御文字、制御キャラクタとも呼ばれます。画面や印刷時には表示されませんが、特別な動作(制御)を行うために使う文字です。
代表的なものを下に示します。
| 16進数 | コード名 | 名称 | 説明 |
|---|---|---|---|
| 00 | NUL | NULL | ヌル(無視する文字) |
| 08 | BS | Back Space | 後退 |
| 09 | HT | Horizontal Tabulation | 水平タブ |
| 0A | LF | Line Feed | 改行 |
| 0C | FF | Form Feed | 改ページ |
| 0D | CR | Carriage Return | 復帰 |
| 1B | ESC | Escape | エスケープ(拡張) |
3.2 JISコード
上記ASCIIコードは7ビットでしたが、日本用にこれを8ビットに拡張したのがJIS X 0201です。
表で示すと下のようになります。

A1からDFに片仮名が割り当てられています。
この20〜7E、A1〜DFの文字は、「半角文字」と呼ばれています。
その後、漢字を扱えるように2バイトで定義されたJIS X 0208が決められました。
第1バイト目は16進数で21〜7Eに、第2バイト目も16進数で21〜7Eに割り当てられています。
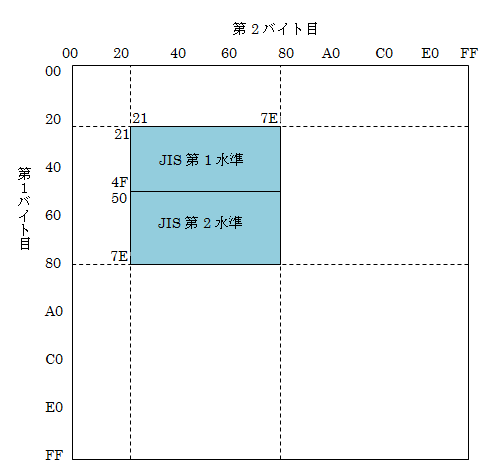

全部で、94×94=8,836文字が収容可能です(16進数21〜7Eの範囲は10進数で94)。
前半に非漢字・JIS第1水準漢字、後半にJIS第2水準漢字を含んでいます。
情報処理学会のWebで文字コード表(PDF、サイズ3.1MB) が公開されています。
この2バイトで構成される文字は、「全角文字」と呼ばれています。
日本語固定幅(等幅)フォントでは、半角文字の文字幅は全角文字の半分になっています。
3.3 シフトJISコード
上記2バイトで構成されたJISコードと同じ文字順番で、右下にシフトしたものです。
第1バイト目は81〜9F、E0〜FC、第2バイト目は40〜7E、80〜FCとなります。なお、第1バイト目がF0〜FCの範囲は拡張領域です。
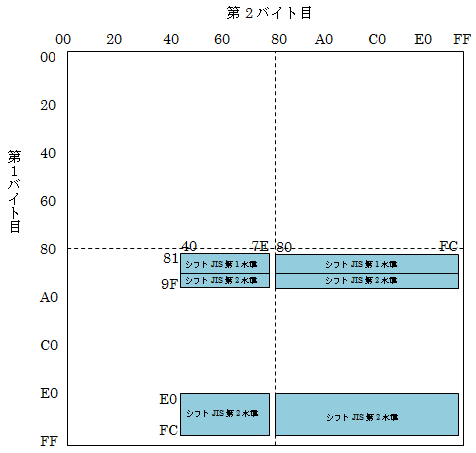
第1バイト目からA0〜DFが除かれているのは、半角カタカナのコードと重ならないようにするためです。
これにより、半角文字(1バイト文字)と全角文字(2バイト文字)が混在した文字列データでも、先頭から順番に処理すれば半角文字と全角文字を切り分けることができます。
シフトJISコードは、長い間MS WindowsやMac OSの標準文字コードとして使われてきました。
3.4 Unicode
ユニコードと呼びます。
世界中の文字を1つの文字コード表に収めようとして規格されました。
Windows NT/2000/XP 以降のWindowsとMac OS X で標準文字コードになっています。
当初は1文字は2バイト固定でしが、現在は拡張され、2バイトを超えるようになりました。登録文字数も10万字を超えています。
一般的に、Unicodeは先頭に U+ を付けて表記します。
文字の割り当ては、概略で下表のようになっています。
| Unicode | 文字の割り当て |
|---|---|
| U+0020〜 | 基本ラテン |
| U+0080〜 | ラテン - 1 補助 |
| U+0100〜 | ラテン拡張 A |
| U+0180〜 | ラテン拡張 B |
| U+0250〜 | IPA 拡張 |
| U+02B0〜 | スペース調整文字 |
| U+0300〜 | 結合分音記号 |
| U+0370〜 | ギリシャ |
| U+0400〜 | キリル |
| U+0530〜 | アルメニア |
| U+0590〜 | ヘブライ |
| U+0600〜 | アラビア |
| U+0900〜 | デバナガリ |
| U+0980〜 | ベンガル |
| U+0A00〜 | グルムキー |
| U+0A80〜 | グジャラート |
| U+0B00〜 | オリヤー |
| U+0B80〜 | タミール |
| U+0C00〜 | テルグ |
| U+0C80〜 | カナラ |
| U+0D00〜 | マラヤラム |
| U+0E00〜 | タイ |
| U+0E80〜 | ラオス |
| U+0F00〜 | チベット |
| U+10A0〜 | グルジア |
| U+1100〜 | ハングル字母 |
| U+1E00〜 | ラテン拡張追加 |
| U+1F00〜 | ギリシャ拡張 |
| U+2000〜 | 一般句読点 |
| U+2070〜 | 上付き/下付きの文字 |
| U+20A0〜 | 通貨記号 |
| U+20D0〜 | 記号用結合分音記号 |
| U+2100〜 | 文字様記号 |
| U+2150〜 | 数字の形 |
| U+2190〜 | 矢印 |
| U+2200〜 | 数学記号 |
| U+2300〜 | その他の技術用記号 |
| U+2400〜 | 制御機能用記号 |
| U+2440〜 | OCR |
| U+2460〜 | 囲み英数字 |
| U+2500〜 | 罫線素片 |
| U+2580〜 | ブロック要素 |
| U+25A0〜 | 幾何学模様 |
| U+2600〜 | その他の記号 |
| U+2700〜 | 装飾記号 |
| U+3000〜 | CJK 用の記号および分音記号 |
| U+3040〜 | ひらがな |
| U+30A0〜 | カタカナ |
| U+3100〜 | 注音字母 |
| U+3130〜 | ハングル互換用字母 |
| U+3190〜 | 漢文 |
| U+3200〜 | 囲み CJK 文字/月 |
| U+3300〜 | CJK 互換文字 |
| U+4E00〜 | CJK 統合漢字 |
| U+AC00〜 | ハングル |
| U+E000〜 | 私用領域 |
| U+F900〜 | CJK 互換漢字 |
| U+FB00〜 | アルファベット表示形 |
| U+FB50〜 | アラビア表示形 A |
| U+FE20〜 | 統合半角記号 |
| U+FE30〜 | CJK 互換形 |
| U+FE50〜 | 小字形 |
| U+FE70〜 | アラビア表示形 B |
| U+FF00〜 | 半角形/全角形 |
| U+FFF0〜 | 特殊文字 |
| U+10000〜 | 補助多言語面 |
| U+20000〜 | CJK統合漢字拡張B |
| U+2A700〜 | CJK統合漢字拡張C |
| U+2B740〜 | CJK統合漢字拡張D |
| U+2F800〜 | CJK互換漢字補助 |
表中のCJKとはChina(中国), Japan(日本), and Korea(韓国) の略です。
U+0000〜U+FFFFの範囲は基本多言語面(Basic Multilingual Plane、略してBMP)と呼ばれます。
ユニコードコンソーシアム (The Unicode Consortium)のWeb に文字コード表があります。
ユニコードコンソーシアムの表の見方ですが、例えばAlphabetic Presentation Forms の表で

左上の「ff」は、表上側に"FB0"と記述されており表左側に"0"と記述されています。表左側の"0"はUnicodeの最下位桁の値であり、表上側の"FB0"は最下位桁より上の値です。そのため、「ff」のUnicodeはU+FB00となります。同様に「fi」のUnicodeはU+FB01となります。
4. UnicodeのIVS
IVSとは Ideographic Variation Sequence の略で、異体字を表示するためのしくみです。
通常のUnicodeの後に、異体字に割り振られた異体字セレクタと呼ばれる値を付けることにより、異体字を識別します。
異体字セレクタの値としては、U+E0100〜U+E01EFが使われます。
例えば、![]() の異体字
の異体字![]() は「U+6271 U+E0101」となります。
は「U+6271 U+E0101」となります。
「U+6271」の後に異体字セレクタ「U+E0101」があるので、これは「U+6271」の異体字だとわかり、通常の字形ではなく異体字としてフォントに登録されている字形を使います。
Windows 7 及び Mac OS X 10.7 で対応しています。但し、アプリ側での対応も必要ですし、IVSに対応したフォントも必要です。
IVSに対応していないアプリでは異体字を表示できませんが、異体字でない通常の文字が表示されるので文章としては意味をなします。
現在、IVSのコレクションとして Adobe-Japan1 と Hanyo-Denshi の2種類が規定されています。この2つに互換性がないため、Adobe-Japan1 IVSコレクションのフォントかそれともHanyo-Denshi IVSコレクションのフォントかを知った上で使う必要があります。
Adobe-Japan1 用のフォントとしてはAdobe社のフォント「小塚明朝 Pr6N」「小塚ゴシック Pr6N」などが、Hanyo-Denshi用のフォントとしてはIPA(独立行政法人情報処理推進機構)が公開しているフォント「IPAmj明朝」などがあります。
TTEdit用のIVS対応TrueTypeフォントを作成するファイルをダウンロードすれば、TTEditでもIVSフォントを作成できます。
Copyright © 2015 Musashi System All Rights Reserved.